

Can LLMs earn $1M from real freelance coding work?
A new benchmark tests AI’s ability to complete real-world software engineering tasks.

Welcome to the latest issue of Engineering Enablement, a weekly newsletter sharing research and perspectives on developer productivity.
This week I read SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?, a new paper from OpenAI that evaluates how well frontier AI models perform on real-world software development tasks.
My summary of the paper
In just two years, language models have advanced from solving basic textbook computer science problems to winning gold medals in international programming competitions—so it can be difficult for leaders to understand the current state of AI’s capabilities. In this paper, the researchers provide the first benchmark of this kind.
While previous coding benchmarks focused on isolated, self-contained tasks, this new benchmark (called SWE-Lancer) shows how AI models handle real-world tasks. In doing so, it also provides an understanding of AI’s capabilities today.
Creating the benchmark
To measure how well AI can handle real-world tasks, the researchers collected over 1,400 freelance jobs posted on Upwork. Each task had a real dollar value attached—ranging from $250 to $32,000—and collectively, the tasks were worth over $1 million. By tying performance to actual dollar values, this study provides a clearer picture of AI’s current economic impact potential.
The tasks were split into two types:
1. Individual contributor software engineering tasks — “Can AI fix this bug or build this feature?” These ranged from quick 15-minute fixes to multi-week feature requests. The AI model was given the issue description and access to the codebase, then had to write code to solve the problem. Human engineers built tests to check whether the AI’s solution actually worked.
2. Engineering manager tasks – “Can AI pick the best solution?” In these, the AI had to review multiple freelancer submissions for a job and choose the best one—just like a hiring manager would. The correct answer was based on what the original manager picked.
To be thorough, the researchers paid 100 professional software engineers to create and verify tests for every task. Each test was triple-verified.
They measured the success of each AI model using:
Pass rate: How many tasks it completed successfully
Earnings: The total dollar value of tasks it could complete
Performance variations: How results changed when models had more tries, more time, or access to tools
This methodology provides a realistic picture of how well current AI models can handle the kinds of software engineering tasks that companies actually pay humans to do.
Performance and findings
The researchers evaluated three frontier models on the selected tasks:
Claude 3.5 Sonnet
OpenAI's GPT-4o
OpenAI's "o1" with high reasoning effort
Here’s what they found:
1. All models underperform human engineers
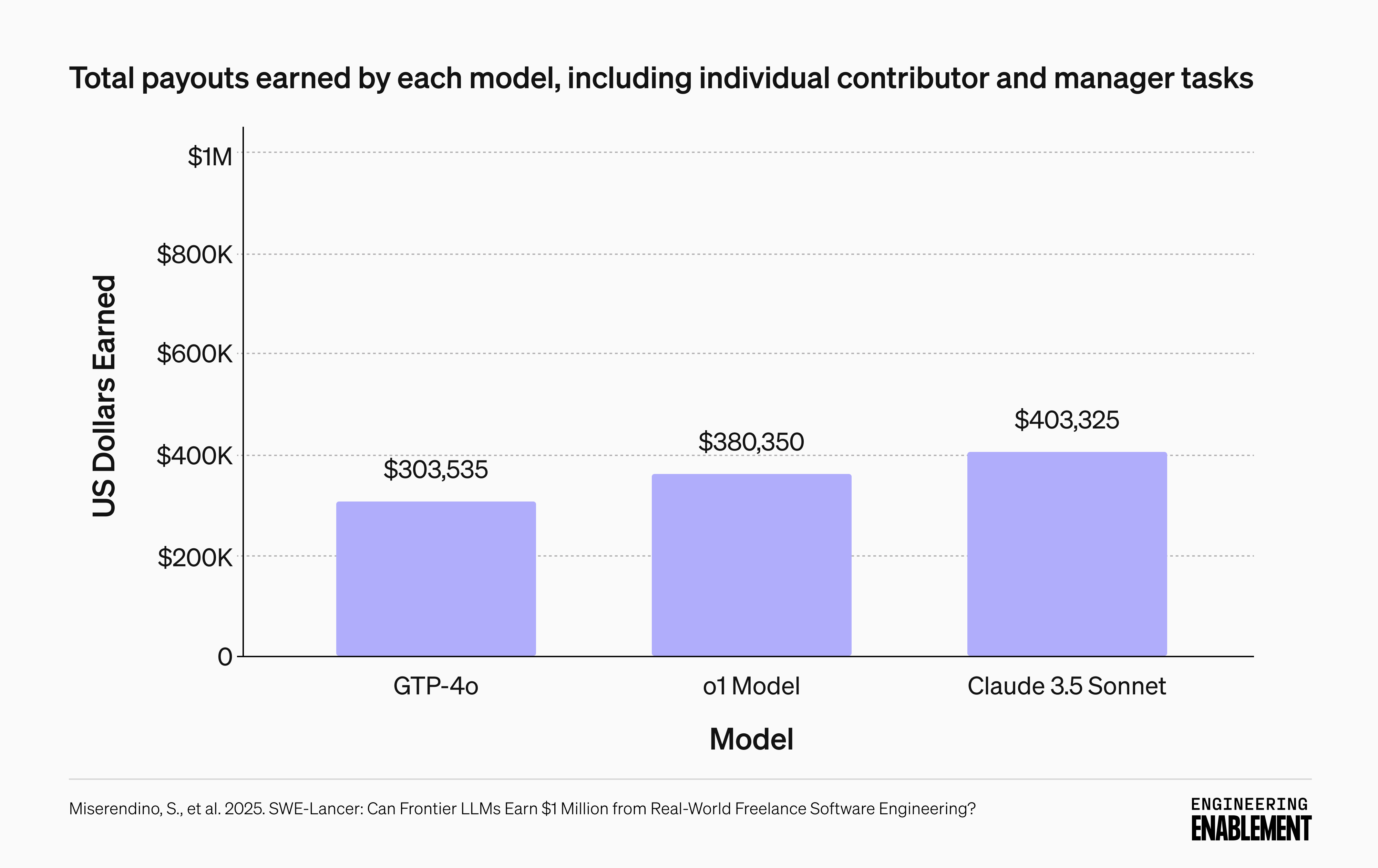
As shown in the table below, all models earned well below the full $1 million USD of possible payout. Even the best-performing model—Claude 3.5 Sonnet—earned approximately $403,000 of the possible $1 million total, solving only 33.7% of all tasks.
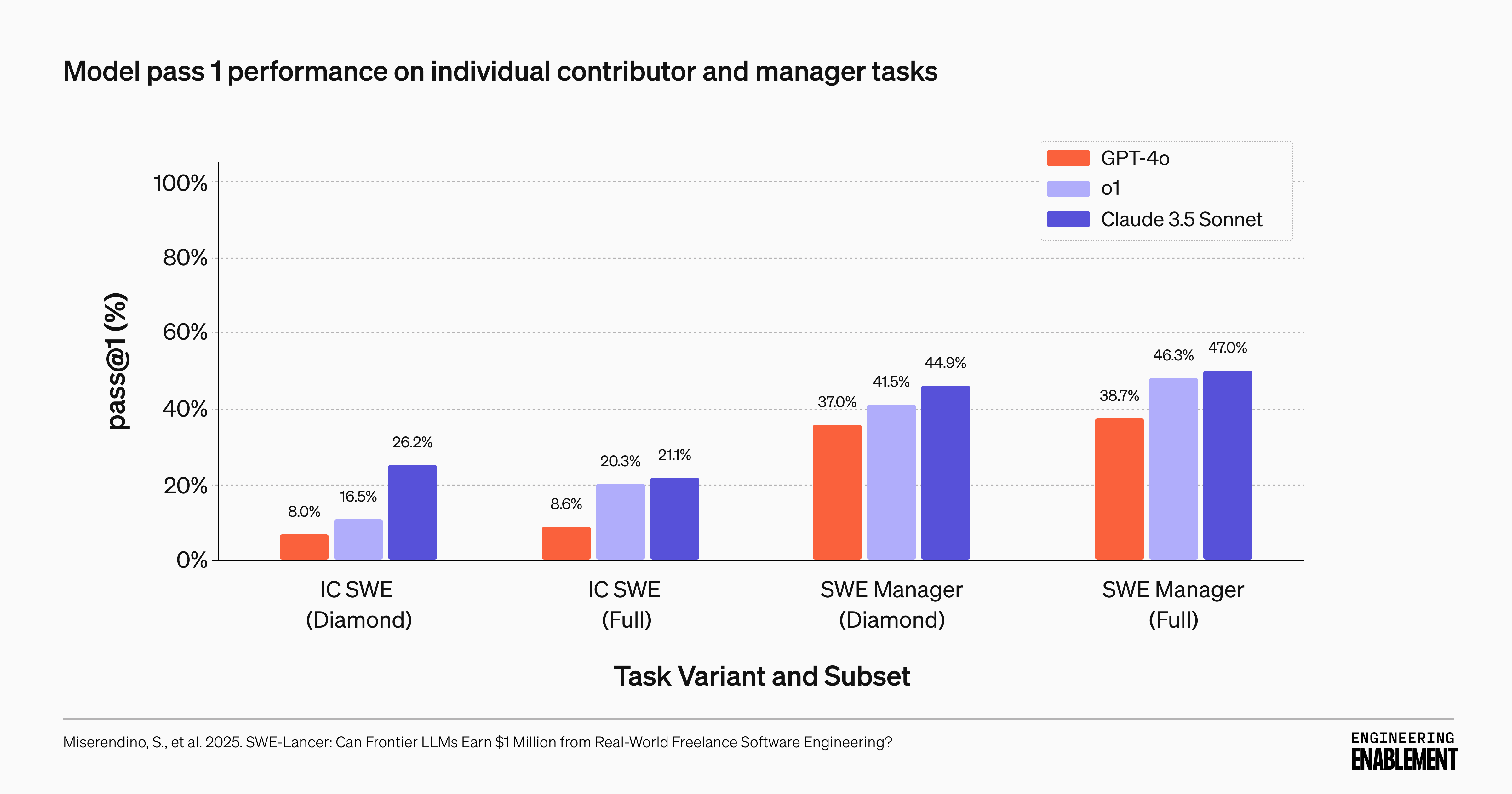
2. All models perform better at management tasks than at coding
All models were significantly better at picking the best solutions than they were at creating the best solutions. For example, Claude 3.5 Sonnet successfully completed 47% of management tasks but only 21.1% of implementation tasks.
This suggests that AI might first aid engineering teams by helping with code reviews and architectural decisions before it can reliably write complex code.
3. Performance improves with multiple attempts
Allowing the o1 model 7 attempts instead of 1 nearly tripled its success rate, going from 16.5% to 46.5%. This hints that current models may have the knowledge to solve many more problems but struggle with execution on the first try.

4. More computation time helps, especially on harder problems
Increasing "reasoning effort" improved o1's performance from 9.3% to 16.5%, with even bigger gains on complex tasks. This indicates that current limitations might be computational rather than fundamental.
5. Models show significant differences in capabilities
Claude 3.5 Sonnet (31.7%) drastically outperformed GPT-4o (2.4%) on UI/UX tasks, suggesting important differences in how these models handle visual and interface elements.
Final thoughts
While today's best AI models can successfully complete some real-world tasks, they still cannot reliably handle the majority of complex projects. This study demonstrates both the incredible progress AI has made and the significant challenges that remain before teams can fully automate coding tasks.
Most importantly, the benchmark introduced in this paper provides a concrete way to measure AI progress going forward, helping leaders better understand and forecast AI's current ability and impact.
Who’s hiring right now
This week’s featured DevProd & Platform job openings. See more open roles here.
Adyen is hiring a Team Lead - Platform | Amsterdam
Scribd is hiring a Senior Manager - Developer Tooling | Remote (US, Canada)
Rippling is hiring a Director of Product Management - Platform | San Francisco
UKG is hiring a Director and Sr Director of Technical Program Management | Multiple locations
Snowflake is hiring a Director of Engineering - Test Framework | Bellevue and Menlo Park
Lyft is hiring an Engineering Manager - DevEx | Toronto
That’s it for this week. If you know someone who would enjoy this issue, share it with them:
My N=1 experiment with all publicly available solutions, including raw frontier models and specifically built solutions for AI development tasks like v0 or bolt, proves that while I can get some help, especially in terms of ideation, the more specific I become about the requirements, the less useful the results are.
What a very interesting study and nicely concise write-up! One thing that you might want to watch out for here---it looks like all three of your figures are direct reproductions of the authors' Fig 5, Fig 6, and Fig 7, but branded with the name of this newsletter. Can I suggest either just directly using their figures (fair use) or at least making a note that gives credit, e.g., "minimally adapted from [citation]"? I found myself mistakenly thinking that you had actually put together the figures from tables in their paper because they had not provided visualizations.