

How Faire's platform team built an AI code review agent
A closer look at how Faire is putting AI to work beyond just code generation.


Welcome to the latest issue of Engineering Enablement, a weekly newsletter sharing research and perspectives on developer productivity.
🗓 Sign up for our live discussion later this month on how AI is changing the role of Platform teams. Register here.
Much of the conversation around AI’s impact centers around code generation. But code generation is just one of many opportunities where AI can be leveraged. To realize the full benefits of AI, organizations need to think bigger and explore how AI can speed up and support every part of the software development lifecycle.
The review process is a perfect example of where AI might be able to make a difference. Code reviews are important for maintaining quality, but they also create a bottleneck that slows teams down. This makes the review process an ideal candidate for AI assistance.
Luke Bjerring, a Principal Engineer at Faire, saw this opportunity. Rather than purchasing an existing tool, his team decided to build their own solution: "Fairey," an AI-powered code review agent. Today, Fairey handles about 3,000 code reviews every week across Faire's entire codebase.
DX's Deputy CTO Justin Reock recently sat down with Bjerring to learn more about this decision and how Fairey works in practice. Their conversation offers a case study of a company successfully using AI to tackle development challenges beyond code generation. For other organizations exploring ways to get more out of AI, this conversation with Faire provides both inspiration and helpful details about how their tool works.
Over to Justin.
Though essential to maintain quality, code review remains one of the most stubborn bottlenecks in the SDLC, causing context switching during feedback cycles, and creating additional work for engineers in the form of the review itself.
At Faire, engineering leader Luke Bjerring set out to improve the review process for their roughly 300 engineers, by building an in-house, AI-powered, always-on code review solution called “Fairey.” This solution would span their monorepos for frontend (TypeScript) backend (Kotlin), iOS, Android (Kotlin), data science (Python) and myriad smaller repos for stuff like Terraform configs. Fairey now completes roughly 3,000 code reviews a week, and the project is considered a success, with additional iteration and improvements ongoing.
The solution was built to accelerate pull request (PR) feedback while maintaining a high standard of code quality. Fairey can review style and code coverage, flag breaking changes, and detect build issues. It then posts actionable comments directly into PR threads. Developers get instant feedback on their changes when they initiate a PR, significantly reducing feedback cycle time and allowing engineers to spend more time on complex challenges versus nitpicks during review.
The result has been faster reviews, cleaner PRs, and a culture shift that’s meaningfully reshaping engineering productivity. In this article, we’ll explore how Bjerring and his team envisioned and created Fairey, and the impact it has had on their engineering productivity and culture.
For Faire, a bespoke solution was the best choice
Bjerring looked into several off-the-shelf automated code review solutions, but was unable to find a ready-made product that he felt would lead to a true paradigm shift in the way the review process was being handled. Midway through this evaluation, he felt the seismic shift in quality behind LLMs, which have gone from flaky, temperamental toys to powerful, efficient tools in a remarkably short time.
As new off-the-shelf code review solutions began to emerge, it was clear to Bjerring that, although these tools were good at solving generic problems, he would need something bespoke to Faire’s domain to truly improve their process. There simply wasn’t enough context awareness and domain-specificity for the tools to solve real business challenges. As he put it, “We found that we needed to tailor instructions and MCP tools for the reviews to be effective. Most off-the-shelf solutions were great at generic reviews, but often made suggestions we didn't care about. Without customization, we were never going to reach the desired level of efficacy.”
The rate at which AI tools are being released was a factor as well - how could he be sure that whatever Faire invested in wouldn’t become obsolete? Bjerring notes that “The number of products that are coming out of every AI vendor is so rapid that it becomes a risk. But it's also very easy to stitch these things together [internally.]”
It was clear that prototyping a solution in-house would be the best path towards a relevant and impactful solution. In the end, Bjerring’s team was able to prototype a solution in a few weeks that integrated Slack, GitHub, and OpenAI APIs (ultimately overhauled to use Claude Code) to form a functional review pipeline. Faire does continue to evaluate off-the-shelf solutions, as Fairey is still most adept at highly-tailored reviews, while emerging solutions may prove useful for other scenarios.
Notably, Bjerring understood that gaining new AI skillsets would benefit the future capabilities of his team, so the creation of this solution was both an efficiency and educational pursuit. “There’s a strong conviction that learning these skills for our engineering team is a really important part of the overall culture shift. So, yes, we could buy off-the-shelf solutions and eventually they’ll come up to the level of quality that we’re happy with for achieving most things. But we want a paradigm shift in the way the engineers are approaching the work,” he notes.
Start small and prove ROI fast
When Bjerring first prototyped Fairey, and later its Claude Code successor, dubbed “Project Cyberpunk” because of its modular and futuristic nature, the idea behind the solution was simple: use an LLM to automate parts of the pull request review process. Within days, the prototype was generating and reviewing production-quality code.
Pitching leadership on auto-review ROI was easy because Faire’s metrics showed that ‘Time to Review’ was the long pole in the tent, and Faire was able to automate reviews that check for backwards-incompatible changes during a three-day hackathon. Extrapolating from there, Bjerring expected to be able to offer substantial automated coverage of Faire’s most common workflows. That proof of productivity earned the project legitimacy and focus, as well as the ability to have a few engineers help work on the next generation of the tool.
Build a fully embedded workflow, not disjointed tasks
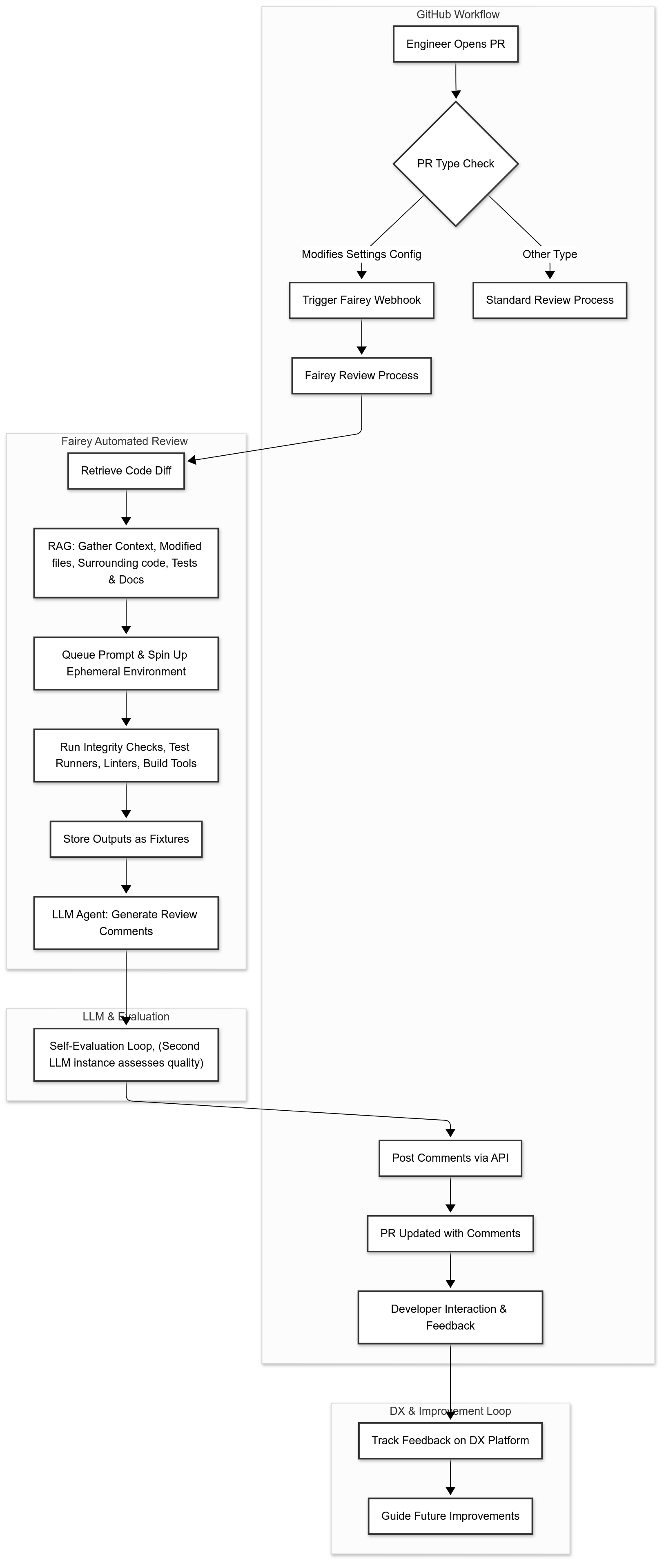
Today, Fairey’s code review process is fully embedded: any engineer who submits a certain type of pull request, like modifying a settings configuration, automatically triggers Fairey’s review process. It’s conditional, in that not every code review goes through Fairey, but deeply impactful where it counts.
Fairey’s architecture is designed to deliver consistent, context-aware code reviews automatically within Faire’s GitHub workflow. When a PR is opened, a GitHub webhook initiates a Fairey review. Fairey then retrieves the code diff, and uses RAG to gather relevant contextual information such as modified files, surrounding code, related tests, and documentation, which helps the model better understand the change. A prompt is queued which spins up an ephemeral environment tailored to Faire’s backend.
Fairey then invokes several defined functions inside that environment, including test runners, linters, and build tools, to assess the integrity of the code. The outputs from these steps are stored as “fixtures” - structured, versioned snapshots of the environment and responses, to ensure auditability and reproducible runs. This design allows developers to trace exactly how a review was generated, and to replay the pipeline if needed.
Using the collected context and fixture data, the LLM agent then generates concise, actionable code review comments. These are passed through a self-evaluation loop, where a different LLM instance assesses the quality of each suggestion to ensure relevance and clarity. Finally, the comments are posted directly into the pull request via the GitHub API. Fairey then uses the DX platform to track feedback and guide future improvements.
Faire uses DX as both a guiding framework for Fairey itself and as a means for assessing Fairey’s overall impact on developer productivity. It keeps track of the number of reviews that are performed by Fairey, as well as Fairey’s overall impact on productivity drivers such as review turnaround time. Quality metrics from Fairey’s self-evaluation loop are collected as well, which makes it easier for Bjerring’s team to understand where Fairey can be improved.
Focus early efforts on predictable, high-leverage tasks
To mitigate problems with complexity, Faire focused their automation on PR types where impact would be highest and instruction quality could be guaranteed:
Large PR Reviewers: To avoid low-quality reviews due to overwhelming size, any PR over 500 lines gets broken down into smaller chunks. The LLM suggests how to restructure the PR to optimize for review.
Test Coverage Reviewers: Automated reviews check whether sufficient test coverage exists and flag if not, and they suggest test cases that should be added.
Settings Configuration Reviewers: Domain-specific logic ensures these common, high-traffic PRs follow best practices.
Strictly speaking, these aren't bug-finders as much as they are coaching agents, nudging engineers toward better PR hygiene and reducing review latency.
Build both technical and behavioral muscle
Bjerring reflects that convincing engineers to adopt these workflows wasn’t instant. Some had bad experiences with LLMs in their early inception. Others felt AI might diminish the creative joy of development. The early results helped to reframe that thinking amongst engineers. As Bjerring observes, “Minds change once developers have their personal "wow" moments, whether that's AI catching a bug, totally nailing a background task, or just automatically patching their PR in reaction to broken builds. After those moments, most developers are hooked.”
Faire's leadership built excitement through grassroots wins: fixing real bugs, accelerating real tickets, and integrating directly into daily workflows like Slack threads or GitHub PR comments. Ultimately, engineers should be allowed to experiment and iterate. AI efficacy increases with usage fluency.
Treat prompt libraries like software
In practice, Bjerring observed that even sophisticated LLM code reviewers have limitations:
Lack of Memory: LLMs forget organizational changes. Without persistent memory or active prompt updates, reviews can go stale fast.
Prompt Rot: As codebases evolve, reviews need to be re-tuned. Otherwise, a once-useful prompt can become a productivity drag.
Tool Fatigue: Teams who’ve been burned by underwhelming pilots may need convincing to try again.
Bjerring recommends only maintaining a small, high-ROI library of automated reviews, possibly in a version control system, and encouraging engineers to write better prompts by imagining they’re instructing a new hire, not an omniscient AI.
Final advice: “Start yesterday”
Bjerring’s parting advice underscores the urgency of making these investments immediately. As he puts it, “Start yesterday. It’s crazy how quickly you can stitch together a chatbot that has the connections it needs to get you most of the way through.”
Further, you don’t need a full team or even custom models to see value. API-accessible solutions like Claude Code are good enough to achieve meaningful wins. The hardest part is often the plumbing, in the case of Faire, connecting Slack, GitHub, Notion, and CI/CD. Even so, this is a low lift compared to the upside. Bjerring adds that “The models are only going to get better. Since efficacy is contingent on quality context and tools, investing now will pay more dividends when even better models ship - like the recent GPT-5 launch.”
Faire is now working on a new module for Fairey, a swarm coding workflow which so far has allowed them to collapse 2-month migrations into 2-day sprints. At the time of this article, roughly 20% of engineers at Faire have successfully merged a fully autonomous PR. This is what’s possible when you give your engineers autonomous assistants who never sleep and never context switch.
Faire is hiring: See open roles here.
That’s it for this week. Thanks for reading.
-Abi
 | A guest post by
|