

Measuring engineering productivity in the AI era
How to track AI's impact, keep an eye on quality, and use metrics to drive action.


Welcome to the latest issue of Engineering Enablement, a weekly newsletter sharing research and perspectives on developer productivity.
🗓 Join us for an upcoming live webinar on how AI is changing the role of platform engineering.
We recently held a live discussion on how to measure engineering productivity in the AI era. It’s the topic that everyone’s wrestling with: How do we measure the impact of AI? How do we avoid overspending? And how do we keep an eye on AI’s impact on quality?
Our conversation covered these questions. We introduced the AI Measurement Framework for measuring the impact of AI and provided guidance on topics such as tracking AI-generated code and measuring agents.
This week’s newsletter excerpts key questions from the conversation. You can also rewatch the full discussion here.
Q: Is there a framework to measure AI’s impact?
Laura: We've been working on this problem for months, collaborating with leading researchers and several AI code assistant vendors. In addition to this expert input, hundreds of organizations have also provided valuable feedback. Ultimately, our goal has been to offer a research-backed recommendation for how organizations should approach measurement in the AI era. What we've developed builds on the DX Core 4—the framework we published last year for measuring engineering productivity—and extends it specifically for AI measurement.
We developed the AI Measurement Framework because we saw that existing approaches were often vendor-specific or overly narrow. Our goal was to create something vendor-agnostic, research-backed, and practical—something that could unite industry practices and meet organizations wherever they are on their AI journey.
The framework focuses on three core dimensions: utilization, impact, and cost.
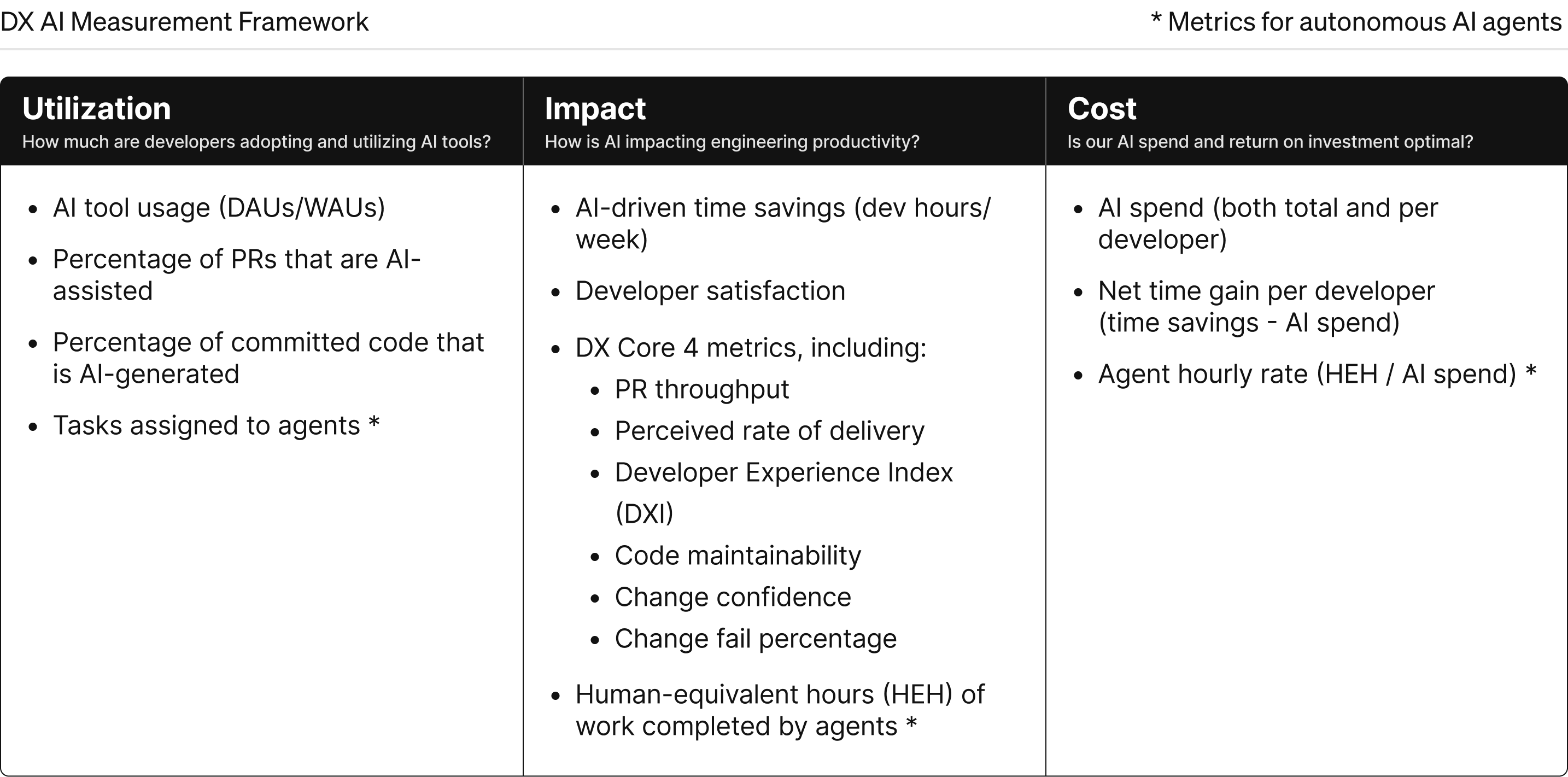
These three dimensions mirror the typical adoption journey of AI tools within organizations:
Utilization is where most organizations start—are users actually adopting the tool? This follows the same logic you’d apply to any dev tool. For a CI/CD tool, you’d look at builds running or automated projects. For AI, you can track metrics like daily active users to understand adoption patterns.
Impact is where we return to those foundational performance definitions that don’t change—the Core 4 metrics. You establish a baseline before introducing AI tools, then track how those values change as developers get onboarded for code authoring and other parts of the software development lifecycle.
Cost ensures you’re investing appropriately. This means checking whether you're spending too much, too little, or just right. Look at license costs, usage-based consumption, training expenses—the full ROI picture. When you examine these dimensions together, you can tell a comprehensive story about what AI is actually doing in your organization.
Abi: This really does mirror the adoption journey Laura described. Organizations typically start with "Let's get these tools enabled and in developers' hands. Let's experiment." Then they move to "Okay, people are adopting these tools—what kind of impact are they having on the SDLC, developer experience, and productivity?"
The cost aspect is just starting to get serious attention, and it needs to. In a world where a single developer can burn thousands of dollars in AI tokens within minutes, organizations are asking critical questions: What's the right spend per developer? Where is AI spend delivering positive net ROI?
Most organizations we're seeing are still in the first two phases—enabling tools, encouraging developers to learn them, and increasing usage maturity. Then they're studying the impact both longitudinally over time and across different tools through vendor evaluations. They want to understand which tools work most effectively for different types of developers, or compare senior versus junior developer outcomes.
Ultimately, organizations want to detach themselves from the marketing, hype, and headlines. They want data grounded in their own organization to have rational discussions about realistic impact expectations and how to extract more value from these tools.
Q: How do you ensure AI isn’t hurting long-term code quality?
Laura: When someone asks me, "How do we make sure that it's not just garbage code?" my response is: "How do you make sure it's not garbage code right now?" We look at metrics like change failure rate, developer satisfaction, change confidence, and maintainability. All of those things together help you get a full picture of AI's real impact, so you don't get fixated on numbers like the percentage of code or acceptance rate.
Abi: One thing we look at closely is code maintainability, which is a perceptual measure—self-reported by developers on how easily they feel they can understand, maintain, and iterate on the code base.
As expected, when more code is written by AI, humans become less knowledgeable about that code. In some cases, we see decreased maintainability scores, which raises the question: "So what? What do we do with that?"
On the one hand, that’s both intuitive and slightly concerning. But on the other, perhaps AI-augmented coding is just the next abstraction layer. We started writing machine code, then moved to higher-level abstractions.
Q: How do you actually track AI-generated code?
Abi: A lot of organizations want to track how much of their code is being generated by AI. One proxy metric we've seen is acceptance rate. However, our point of view, and the consensus among many practitioners and researchers, is that acceptance rate is incredibly flawed because when developers accept code, much of it is often later modified or deleted—and therefore human-authored.
For tracking AI-authored code, tagging the code and PRs is one easy way to start. Some AI tool vendors have, or are developing, different techniques and technologies to assess this. At DX, we've been developing technology that provides observability at the file system level, looking at the rate of changes to files to detect changes from human typing versus AI tools making batch modifications. This approach can cross-cut all IDEs, all AI tools, and CLI agentic tools.
Q: How do you gather these metrics in practice?
Laura: There are three main ways to gather these metrics:
1. Tool-based metrics: Most AI tools have admin APIs that allow you to track usage, spending data, and token usage, or code suggestions and acceptances. System-level metrics from other tools in your development process like GitHub, JIRA, Linear, your CI/CD tools and build systems, and incident management systems will help you see other shifts that result from AI adoption, like changes in pull request throughput or review latency.
2. Periodic surveys: Periodic surveys, typically done quarterly, are effective for capturing longer-term trends. Over time, surveys help track whether the developer experience is improving or degrading as AI usage scales. Surveys are also very useful to measure data across multiple systems, where tool-based metrics may be unwieldy or impractical. Developer satisfaction and other perceptual measures (such as change confidence, or perceived maintainability of source code) can't be captured from system data, so surveys are the right choice.
3. Experience sampling: Experience sampling involves asking a single, highly targeted question at the point of work. For instance, after submitting or reviewing a pull request, you might ask, “Did you use AI to write this code?” or “Was this code easier or harder to understand because it was AI-generated?” These responses yield granular, in-the-moment feedback that’s difficult to capture through periodic surveys or telemetry alone.
There's usually more than one way to get to a data point. For example, you can look at GitHub PR review data coming from the system to measure PR throughput. You can also ask the question, "In the past month, how frequently have you merged new changes that you were the author of?"
By layering these three methods—tool-based metrics, periodic surveys, and experience sampling—you can build a measurement approach that’s both comprehensive and resilient (DX gives you these out of the box). Each method has its strengths, and together they allow you to cross-validate data and stay grounded in what’s actually happening in your org. This data helps you build a feedback loop that helps you make smarter decisions about your AI strategy as AI becomes a deeper part of your development processes.
Q: How should we think about measuring AI agents?
Abi: There's a lot of industry discussion around needing clear definitions of what an agent is. There's a distinction between AI-powered auto-complete in an IDE versus newer tools that are autonomous loops completing entire end-to-end tasks, even discovering tasks autonomously.
The really interesting question we've been wrestling with is: Do we begin to look at agents as people in terms of measuring the agent's productivity? Are we measuring the agent's experience?
As of now, our recommendation is to treat agents as extensions of people. We're treating people as managers of agents, people plus agents as teams, so we should measure the efficacy and productivity of agentic software development by looking at agents as extensions of people, and measuring them as a group, as a team.
Q: How do you use these metrics to drive action?
Abi: It depends on where you are in your journey.
We see folks just starting out with utilization metrics at the beginning of their rollout to drive enablement, training, and communications to get developers using these tools.
We see a lot of organizations using this data to evaluate tools. There's a new tool every day in the AI space, so taking a data-driven approach to evaluations is valuable.
We're also seeing folks use the data for planning and rollout strategy—what parts of the organization do we focus on? What tools work best for different types of developers across our organization?
And lastly, folks are using this data to understand ROI. What impact are we seeing right now in our organization? That's a really important question every board and corporation is trying to answer. Being able to show up to that conversation with real data and a narrative is really valuable.
Final thoughts
Instead of focusing on hype and headlines, focus on what the data is saying. Treat this as an experiment with a scientist's mindset. Establish a baseline using the Core 4 metrics or your current productivity measures, then monitor how AI impacts them alongside utilization and cost for a complete picture.
The framing and rollout is equally crucial. These tools enable invasive telemetry into developers' daily work, naturally raising concerns. With organizations pushing adoption from the top down and even mandating AI adoption, there's pressure and fear around becoming obsolete. It's essential for leaders to be proactive in communicating about measurement use. Be clear about what you are and aren't using this data for, and ensure this is ultimately about helping the organization and all developers make this transition in a rational, data-driven way.
Finally, remember: data beats hype every time. When you're pressed to explain why your organization isn't AI-generating 50% of its code, having concrete data from the AI measurement framework provides the strongest foundation for these conversations. These are significant decisions involving substantial budgets, and they deserve to be grounded in evidence rather than enthusiasm.
Who’s hiring right now
This week’s featured DevProd & Platform job openings. See more open roles here.
Dropbox is hiring multiple Infrastructure and AI Dev Tools roles | US (Remote)
Atlassian Williams Racing is hiring a Software Engineer - Engineering Acceleration | Grove, UK
GEICO is hiring a Senior Product Manager - Reliability Platform | Palo Alto, CA; Washington, DC
The New York Times is hiring a Technical Product Manager II - Developer Productivity | NY, NY
ScalePad is hiring a Head of AI Engineering & Enablement | Remote or in-office
That’s it for this week. Thanks for reading.
-Abi