


AI-assisted code authoring at scale
How Meta deployed and measured the impact of their AI-assisted code authoring tool.

This is the latest issue of my newsletter. Each week I share research and perspectives on developer productivity.
This week I read AI-assisted Code Authoring at Scale, a recent paper from researchers at Meta. Meta developed and deployed “CodeCompose,” an AI-assisted code authoring tool used internally at the company. In this paper, the authors describe how they’ve refined, deployed, and measured the impact of this tool. They also share challenges they’ve experienced along the way.
My summary of the paper
When trained to predict the next part of a code sequence, LLMs can become valuable coding assistants that suggest whole lines or sections of code. If they are trained with an organization's own code, they can provide surface internal knowledge when developers need that information. This is especially beneficial for large, dynamic companies like Meta, where it can be challenging for developers to keep up with the knowledge required to accomplish coding tasks. Making knowledge discovery and code authoring easier offers an interesting opportunity to improve efficiency.
For these reasons, Meta built an AI-assisted code authoring system named CodeCompose to explore the application of LLM technology for code authoring. CodeCompose is based on the InCoder LLM and supports code completion in nine programming languages.
Here’s how the tool was tested, deployed, and measured:
Testing and rollout
Before releasing CodeCompose to engineers, the researchers tested its ability to generate code accurately. They did this by hiding parts of existing code at random and letting the model predict the hidden lines. Then, they compared CodeCompose's results to those of the publicly available InCoder model. CodeCompose's accuracy was 1.4 to 4.1 times better than InCoder's, depending on the programming language.
Meta’s team gradually rolled out CodeCompose so they could measure the effects of the tool at every step using quantitative and qualitative feedback. Specifically, the tool was deployed in stages based on programming languages (e.g., starting with Python, then JavaScript, then C++, and so on). Within each stage (each language), CodeCompose was rolled out to 25% of the developer population until it was enabled for 100% of developers. The rollout took four weeks.
Measuring the impact of CodeCompose
The researchers used a mixed-methods approach to evaluate the impact of CodeCompose. Specifically, they monitored:
Usage: The number of accepted suggestions and the proportion of code that was written by CodeCompose
Perception: How developers perceive CodeCompose in their daily work
Usage (quantitative)
Meta's team decided to measure usage by instrumenting telemetry to track how developers interacted with the tool in the IDE. They tracked things like how often suggestions were shown, whether they were accepted or rejected, and how long the accepted suggestions were. To ensure developers had enough time to see and understand the suggestions, only suggestions displayed for at least 750 milliseconds were counted.
The team’s outcome measures were the acceptance rate of suggestions and the percentage of code typed using CodeCompose. These were chosen because prior research studies have used them, such as one from Google, providing Meta with a benchmark to compare against.
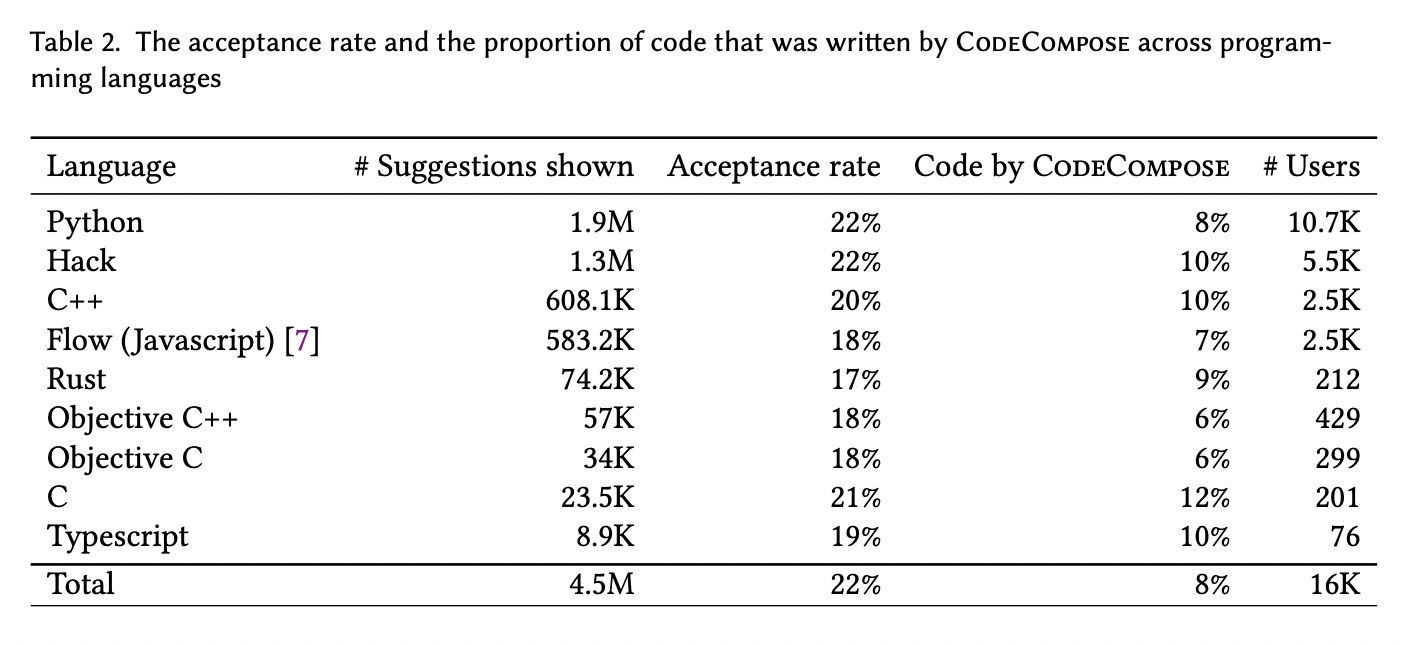
CodeCompose made over 4.5M suggestions across 9 programming languages to 16K engineers. It had an acceptance rate of 22%, which is comparable to rates at Google and GitHub.
Additionally, by tracking the length of each accepted suggestion and the number of characters developers typed, researchers calculated that 8% of the code written was generated from CodeCompose's suggestions. This is higher than the 3% reported by Google.
Perception (qualitative)
At Meta each internal tool has a feedback forum. The researchers conducted a thematic analysis of the user posts within the CodeCompose feedback group, which included coding the posts and then discussing them until a consensus was reached. As starting codes, they used the standard positive, CSAT (Customer Satisfaction), or negative, DSAT (Customer Dissatisfaction).
91.5% of CodeCompose users gave a favorable response and 8.5% gave an unfavorable response. We can see the themes that emerged from feedback in the table below.

Most notably:
23% of the users said CodeCompose helped them discover new APIs, automating tedious tasks such as boilerplate code.
20% said CodeCompose accelerated their coding activity.
15.7% appreciated that CodeCompose suggestions are accurate.
These results suggest that CodeCompose helps developers code faster while also saving them time from searching for APIs and documentation.
CodeCompose was eventually rolled out to 100% of engineers at Meta. During the period of this study, less than 1% of engineers turned the tool off.
Challenges and lessons learned
The authors share some of the challenges and lessons they learned in rolling out CodeCompose:
1. Building trust so developers accept suggestions. If a model generates too many incorrect suggestions, or if it doesn’t generate enough suggestions, developers might lose faith. Meta’s team knew this going into this project, so they trained the model using relevant existing code, not the entire repository. The authors also note that their gradual rollout strategy helped them build trust.
2. Providing the right amount of information. It took several iterations to find the right amount of code to generate at a time, which for Meta was suggesting one line at a time. Also, Meta found that developers were fine with suggestions appearing within 300ms - 500ms, but not beyond 1 second.
3. Evaluating the impact of CodeCompose. Evaluating the usefulness of AI-generated suggestions is a major challenge. For example, acceptance rate may be a good metric to measure product usage but it doesn’t necessarily mean developers are more productive when using the tool - that has to be measured explicitly. Evaluation should go beyond just measuring product impact: it should help understand the cases where the suggestions are inaccurate, or what the pain points are with respect to the user experience, to address those issues. Meta’s team attempted to achieve this by using a suite of metrics.
Final thoughts
I was especially interested to read how Meta measured the impact of CodeCompose. While I agree with their decision to use both qualitative and quantitative methods, I'm skeptical about their approach to qualitative feedback specifically. Relying exclusively on an open feedback channel may give a limited view of developers’ satisfaction with the tool and their use cases with it.
Still this paper and the lessons shared should be a useful source of inspiration for others adopting AI-based developer tools.
Measure the impact of Gen AI tools
Get our guide on how to measure the impact of AI-based developer tools like Copilot.
Who’s hiring right now
Here’s a roundup of recent Developer Experience job openings. Find more open roles here.
Benchling is hiring an Engineer - Developer Productivity | San Francisco
Plaid is hiring a Product Manager - Developer Platform | San Francisco
SEB Bank is hiring a Head of DSI Developer Experience | Stockholm
Uber is hiring a Sr. Staff Engineer (Gen AI) - Developer Platform | US
That’s it for this week. Thanks for reading.
-Abi
> While I agree with their decision to use both qualitative and quantitative methods, I'm skeptical about their approach to qualitative feedback specifically. Relying exclusively on an open feedback channel may give a limited view of developers’ satisfaction with the tool and their use cases with it.
I am curious on how you would measure further.
22% of the 4.5M suggestions means that 3.5M suggestions are declined and I guess this has more distraction for engineers than a boost for productivity.