

Revisiting the DX Core 4 in the age of AI
Why the dimensions that matter most for engineering productivity remain stable, and how to interpret them as AI reshapes work.

Welcome to the latest issue of Engineering Enablement, a weekly newsletter sharing research and perspectives on developer productivity.
🗓 Join me on July 23 for a readout of the upcoming Q2 2026 AI Impact Report. We’ll discuss new findings from DX’s data on AI tool usage, spend, and impact across 500+ organizations. Register here.
When AI coding tools started delivering meaningful results, a predictable question followed from CTOs and engineering leaders: how do we measure the impact? There is a strong instinct to assume that the frameworks built over the last decade no longer apply, and that the age of AI demands a fundamentally different measurement architecture.
I’d push back on that instinct. The evidence suggests the opposite is closer to the truth.
While AI represents a massive paradigm shift in how software is built, it does not alter what engineering organizations are ultimately trying to accomplish. Foundational engineering principles still map to high-level outcomes. How quickly is value delivered? How easy is it for developers to do their work effectively? How stable are the systems? And, ultimately, what is the business impact of the work? Rather than rendering these categories obsolete, the introduction of AI makes anchoring to a stable, outcome-oriented framework more critical than ever.
Engineering leaders are under unprecedented pressure to justify the massive budgets being poured into AI tooling. When executives demand proof that an AI investment is paying off, the immediate temptation is to reach for a shiny new metric that isolates the tool itself. But that is exactly where the risk lies.
The DX Core 4 framework (speed, effectiveness, quality, and business impact) is built around answering these persistent questions. It was designed to give engineering leaders a durable measurement architecture that survives new technology cycles. AI is a significant shift in workflow, but because the framework anchors to macro outcomes rather than the mechanics of coding, it remains stable. If anything, the rise of AI makes this type of durable framework more important, not less.
This article makes three related arguments:
First, the high-level dimensions of engineering productivity remain remarkably stable, even as AI transforms how software is built.
Second, AI-specific telemetry should be treated as diagnostic context rather than a replacement for outcome-oriented measurement.
Finally, while many traditional engineering metrics remain valuable, the behaviors that generate them are changing, and disentangling those signals requires triangulating across the layered structure of diagnostic, system, and outcome metrics.
The Core 4 holds (and here’s why that matters)
The value of anchoring to these four overarching dimensions—speed, effectiveness, quality, and business impact—is that they synthesize key principles from DORA, SPACE, and DevEx into a unified methodology. Core 4 inherits DORA’s focus on delivery outcomes, SPACE’s insistence that productivity is multidimensional, and DevEx’s emphasis on the lived experience of developers—and combines them into a four-dimension framework optimized for executive decision-making.
AI doesn’t change what engineering organizations are trying to accomplish. What it does is make the signals noisier.
As AI coding assistants become standard and agentic workflows begin handling multi-step tasks autonomously, traditional activity metrics shift in ways that can easily mislead. Pull request counts spike, cycle times compress, and code volumes bloat. Engineering leaders who chase these surface-level fluctuations without anchoring to a balanced, outcome-oriented framework risk optimizing for sheer motion rather than actual progress.
This is precisely where a high-level outcome framework proves its utility. I’m using the Core 4 as the specific example here, but the same logic applies to any mature measurement framework aligned to the principles of SPACE. By focusing on outcomes that matter, regardless of how code gets written, the model remains insulated from technology disruptions. This structural design looks increasingly necessary as developer workflows continue to evolve away from manual synthesis and toward intent-driven architecture.
Activity vs. outcome: The role of AI telemetry
To be clear, focusing on measuring stable macro outcomes does not mean engineering leaders should ignore AI adoption and usage. Tracking how developers engage with AI tools is incredibly valuable, but it is critical to understand what those metrics are telling us.
AI adoption, token usage, and the number of tasks assigned to agents are examples of diagnostic telemetry. Like more traditional operational metrics such as pull request size, build duration, or meeting load, they provide visibility into how work is being performed rather than whether it is producing better outcomes.
One way to think about this distinction is illustrated in the image below, whether AI-specific or traditional, helps explain the mechanics of software delivery and the dynamics of the engineering system. By contrast, outcome-oriented frameworks evaluate whether those operating patterns are ultimately translating into better engineering results.
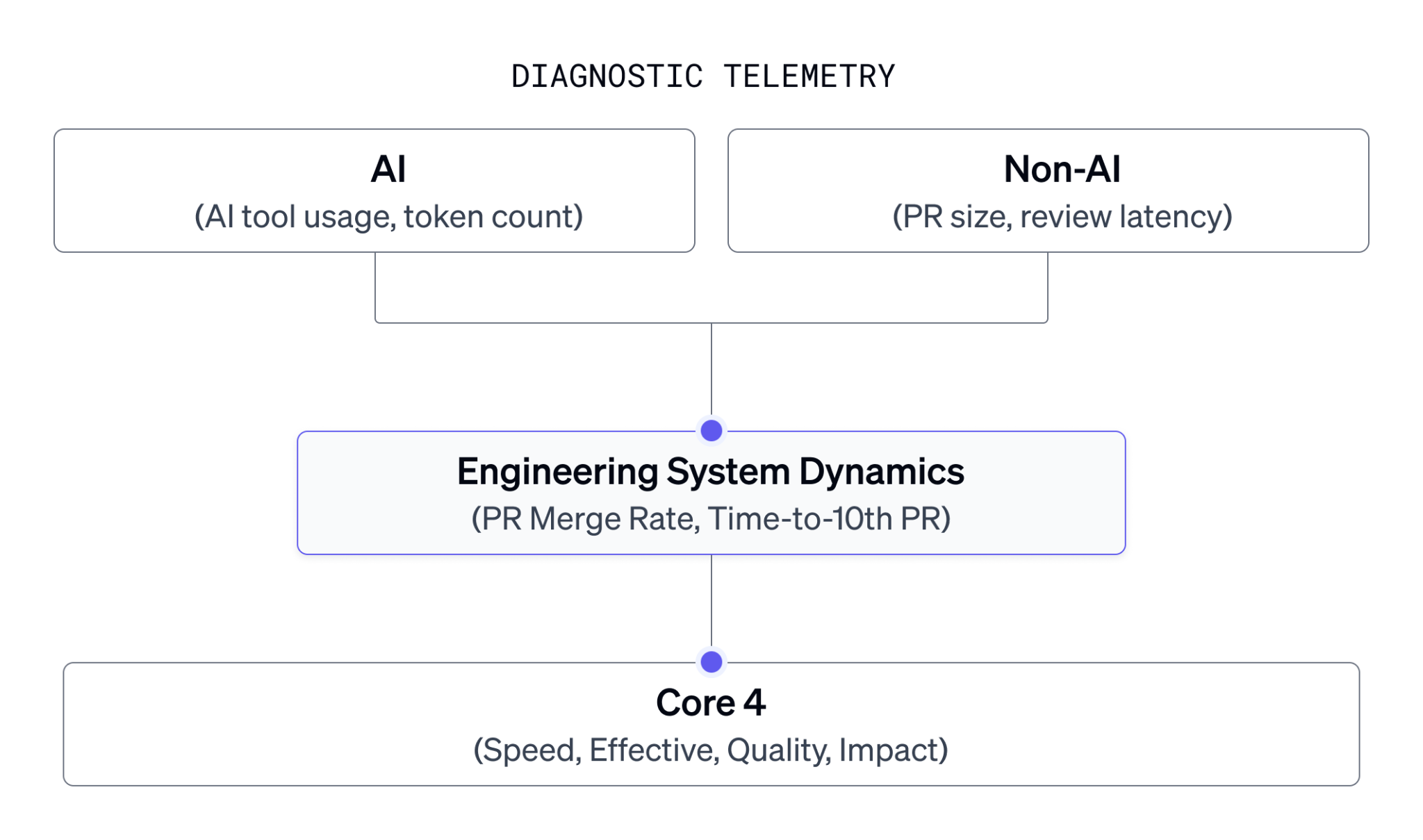
Specialized measurement frameworks can help organize these diagnostic signals. For example, DX’s AI Measurement Framework combines AI-specific telemetry around utilization and cost with outcome-oriented metrics to evaluate AI’s overall impact on engineering organizations. These two classes of measurement answer fundamentally different questions: “How is work being performed?” versus “Is the engineering organization delivering better outcomes?”
The value of tracking AI activity is that it helps us understand the shifting patterns that lead to our outcomes. For example, if a team’s AI adoption spikes to 90%, that metric alone doesn’t prove success. Instead, it serves as a lens to interpret changes in the Core 4: did that spike in adoption correlate with an increase in speed? Did it negatively impact quality via a higher change failure rate? Or did it inadvertently degrade developer effectiveness by introducing new code-review bottlenecks?
Tracking AI telemetry tells us how the work is changing. Tracking the core dimensions tells us if that change is actually delivering results.
When leaders are tasked with proving AI investment ROI, they cannot do it by pointing to adoption spikes or token volume. A high utilization rate means nothing if software delivery stalls or system stability crashes. Outcome-based developer experience metrics aren’t just a way to measure engineering anymore, they may be the most reliable ledger for proving AI value.
PR throughput in the AI era
Of the key metrics within the Core 4, PR throughput has attracted the most debate, both before and after the arrival of AI.
The criticism of PR throughput is entirely fair at the individual level. Not all PRs are created equal in terms of size, complexity, or value. DX developed a methodology called TrueThroughput, which uses AI to normalize these variations by weighting PRs based on actual complexity. Yet, even with that kind of normalization in place, the metric is a poor instrument for evaluating any individual developer’s contribution. I’ve argued this myself, and I’d stand by it. Using PR throughput to assess individuals is the wrong application of the metric.
At the system level, though, it remains one of the most useful signals available. The reason is that it doesn’t just measure output, it measures engineering flow. Whether code in a pull request was written by a human or generated by an AI agent, if it’s moving through review, CI, and deployment without friction, the metric reflects that. If it’s stalling—because review is bottlenecked, builds are flaky, or deployment processes are slow—the metric surfaces that too. PR throughput is a signal for whether an engineering system can move work through, regardless of where that work originates.
It also occupies a unique position among the Core 4 metrics. Unlike measures such as Change Failure Rate or DXI, which continue to evaluate enduring organizational outcomes, PR throughput is directly tied to the mechanics of software delivery. As workflows evolve from code-first to intent-first development, the role of the pull request itself may change substantially, making PR throughput more susceptible to reinterpretation than most other metrics in the framework.
In our own longitudinal research at DX, we found that AI coding tools produced roughly a 7.8% increase in PR throughput across organizations that had adopted them. That’s a real and meaningful signal. It’s also a useful corrective to more optimistic claims about AI’s productivity impact. The gains are real; they tend to be more modest than headline figures suggest, and they vary considerably across different types of work.
The majority of code shipped in production is still written by humans, though that share is shifting. Our research showed that during the first quarter of 2026, the percentage of code generated by AI that reaches production is 27.4% of production code on average. For most engineering organizations today, pull requests remain the primary unit of software delivery, making PR throughput one of the clearest indicators of engineering system flow.
If, and when, the transition to intent-first workflows materializes, the field will likely need a metric that captures innovation velocity as a higher level of abstraction. The Idea-to-Customer velocity metric introduced in the recent EngThrive framework paper is one implementation worth watching as a future key metric for the speed dimension. But even in that future, PR throughput will likely remain a crucial secondary metric for diagnosing system flow.
Evolving the interpretation, not the framework
To recap, the top-level dimensions of the DX Core 4 are stable and as meaningful as ever. The key metrics that support them also continue to hold.
What is changing is the diagnostic layer beneath them, the operational signals that have always helped explain how engineering systems produce those outcomes. AI doesn’t change what good looks like at the outcome level, but it does change the mechanisms that generate many of our familiar diagnostic metrics. The same number can now be produced by very different combinations of human and AI behavior, which means individual diagnostic metrics are noisier than they used to be, and the signals they do provide may relate to outcomes in different ways than they used to.
Take, for example:
PR Merge Rate: Historically, a high merge rate signaled a highly aligned team shipping clean, uncontroversial work. In an agentic workflow, does a 95% merge rate mean the AI is flawless? Or does it mean your human developers are rubber-stamping machine-generated code because they’re too overwhelmed to properly review it?
Time-to-10th-PR: This is currently one of my favorite onboarding metrics because it is highly predictive of a new hire’s long-term success and speed-to-productivity. But its utility faces an unresolved question: if an AI onboarding assistant can help an engineer generate and ship 10 PRs by their second afternoon, does that metric still capture true structural onboarding health? Or does it just track how quickly someone learned to use AI tools?
This is the core challenge. The data points themselves have not changed, but the behaviors that generate them have. AI activity metrics, such as tool adoption or token counts, provide critical context for understanding why traditional engineering metrics move the way they do, but they do not replace those metrics.
Triangulating between diagnostic metrics, engineering system metrics, and high-level outcome metrics is what lets us translate how teams work into whether they’re achieving what they set out to. Building a map of these new patterns—how to interpret them, and what outcomes they predict—will be critical work for engineering teams and researchers moving forward.
Final thoughts
The instinct to reach for entirely new metrics in this age of AI is understandable. AI is genuinely reshaping how software gets built, and it is reasonable to question whether existing measurement frameworks can keep pace.
But our research and data show that the core dimensions of productivity have held up, not because they anticipated AI specifically, but because they were designed around enduring organizational outcomes rather than any particular workflow or technology. Speed, effectiveness, quality, and business impact remain the right questions to ask, whether code is written by a developer at a terminal or generated by an autonomous agent.
What has changed is not what we should measure, but how we should interpret it. AI-specific telemetry provides valuable diagnostic context for understanding how work is evolving, but it does not replace outcome-oriented measurement. Likewise, familiar engineering metrics such as PR throughput, merge rates, or onboarding velocity continue to provide meaningful signals, even as the behaviors that generate those signals shift.
The priority for engineering leaders is not to rebuild their measurement architecture from scratch. It is to learn to interpret existing frameworks through a new lens, one that recognizes the growing role of AI while remaining anchored to the outcomes that ultimately matter.
The framework is stable. The interpretation is where the real work begins.
That’s it for this week. Thanks for reading.
A useful, pragmatic review. Thank you